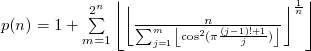Eu podia estar roubando
É isso. Eu podia estar roubando, eu podia estar matando, mas estou aqui escrevendo no blog. Reclamações sobre a periodicidade do blog devem ser enviadas diretamente à Rockstar :)
 Ao falar de GTA, sempre tem quem o associe ao terrorismo islâmico. Mas pra mim, o que incomoda mais é a associação imediata do islã com o terrorismo, em oposição à sociedade ocidental civilizada. Na verdade, já houve um período onde acontecia o oposto, enquanto a ciência florescia na cultura islâmica, os cristãos saqueavam e destruíam em nome da fé (mas na época chamavam isso de cruzadas, ao invés de terrorismo).
Ao falar de GTA, sempre tem quem o associe ao terrorismo islâmico. Mas pra mim, o que incomoda mais é a associação imediata do islã com o terrorismo, em oposição à sociedade ocidental civilizada. Na verdade, já houve um período onde acontecia o oposto, enquanto a ciência florescia na cultura islâmica, os cristãos saqueavam e destruíam em nome da fé (mas na época chamavam isso de cruzadas, ao invés de terrorismo).
Foi nessa época em que viveu Al-Khwarizm (cujo nome deu origem às palavras algarismo e algoritmo), nessa época em que Bhaskara escreveu Lilavati e resolveu a equação de segundo grau, e também nesse período é que surgiram as primeiras demonstrações por indução finita. Mas a influência mais direta que a matemática islâmica teve em mim foi, sem dúvida, através das obras do Júlio César de Mello e Souza, que escrevia com o pseudônimo de Malba Tahan.
 Malba Tahan se inspirava na cultura islâmica pra escrever seus livros de divulgação científica, sendo que o mais famoso deles é o Homem Que Calculava. Num post anterior eu tinha dito que o cálculo do Pi com método de monte carlo tinha sido o segundo puzzle que levei mais tempo pra resolver; pois o primeiro puzzle foi justamente tirado de um dos capítulos do livro: como escrever qualquer número usando apenas quatro quatros. No livro, Malba Tahan mostra as soluções até o 10, que são mais ou menos assim:
Malba Tahan se inspirava na cultura islâmica pra escrever seus livros de divulgação científica, sendo que o mais famoso deles é o Homem Que Calculava. Num post anterior eu tinha dito que o cálculo do Pi com método de monte carlo tinha sido o segundo puzzle que levei mais tempo pra resolver; pois o primeiro puzzle foi justamente tirado de um dos capítulos do livro: como escrever qualquer número usando apenas quatro quatros. No livro, Malba Tahan mostra as soluções até o 10, que são mais ou menos assim:
0 = 44 - 44
1 = 44 / 44
2 = 4/4 + 4/4
3 = (4 + 4 + 4) / 4
...
Eu tinha só dez anos quando li pela primeira vez, e consegui estender a seqüência até o 20. O posfácio do livro dizia que era possível escrever até o 100, mas eu levei mais de uma década até ver a solução completa!
Depois dos 20 primeiros, eu só consegui fazer algum progresso significativo quando estava no colégio técnico. Eu notei que o problema ficava mais simples se eu reduzisse o número de quatros, montando primeiro todas as soluções com um quatro, depois todas com dois quatros, e assim por diante. Eu não sabia na época, mas o que eu estava fazendo era um forward chaining manual. Mesmo assim, eu só consegui fazer os números pares até 100, minha solução tinha um monte de buracos nos ímpares.
 Quando eu estava na faculdade, com os skillz mais afiados, eu larguei mão de fazer manualmente e escrevi um script pra fazer o serviço automaticamente. Eu coloquei no script não só as quatro operações básicas, mas também todas as outras que estão no Concrete Mathematics: raiz quadrada, função piso e função teto, binomiais, potências, fatorial, fatorial crescente e decrescente. A única regra é não usar nenhuma notação que envolva letras (como sin, cos e log; se você permitir log, o problema perde a graça).
Quando eu estava na faculdade, com os skillz mais afiados, eu larguei mão de fazer manualmente e escrevi um script pra fazer o serviço automaticamente. Eu coloquei no script não só as quatro operações básicas, mas também todas as outras que estão no Concrete Mathematics: raiz quadrada, função piso e função teto, binomiais, potências, fatorial, fatorial crescente e decrescente. A única regra é não usar nenhuma notação que envolva letras (como sin, cos e log; se você permitir log, o problema perde a graça).
Meu script conseguiu finalmente resolver todos os números até 100, e até encontrou múltiplas soluções pra eles! Atribuindo um peso a cada operação, eu mandei ele imprimir somente a soluçao mais simples (por exemplo, adição tem peso baixo, piso e teto tem peso alto). A tabela com as respostas está abaixo, junto com o programa que escrevi na época:
Solução gerada pelo script
Script original, escrito em C
O script pode resolver também os 5 cincos, os 6 seis, e qualquer outra combinação, desde que você esteja disposto a esperar o suficiente. O código original é bem ruinzinho, mas na verdade eu me orgulho de achar que meu código escrito há dez anos é ruim, significa que eu aprendi alguma coisa desde então :)
 Ao falar de GTA, sempre tem quem o associe ao terrorismo islâmico. Mas pra mim, o que incomoda mais é a associação imediata do islã com o terrorismo, em oposição à sociedade ocidental civilizada. Na verdade, já houve um período onde acontecia o oposto, enquanto a ciência florescia na cultura islâmica, os cristãos saqueavam e destruíam em nome da fé (mas na época chamavam isso de cruzadas, ao invés de terrorismo).
Ao falar de GTA, sempre tem quem o associe ao terrorismo islâmico. Mas pra mim, o que incomoda mais é a associação imediata do islã com o terrorismo, em oposição à sociedade ocidental civilizada. Na verdade, já houve um período onde acontecia o oposto, enquanto a ciência florescia na cultura islâmica, os cristãos saqueavam e destruíam em nome da fé (mas na época chamavam isso de cruzadas, ao invés de terrorismo).Foi nessa época em que viveu Al-Khwarizm (cujo nome deu origem às palavras algarismo e algoritmo), nessa época em que Bhaskara escreveu Lilavati e resolveu a equação de segundo grau, e também nesse período é que surgiram as primeiras demonstrações por indução finita. Mas a influência mais direta que a matemática islâmica teve em mim foi, sem dúvida, através das obras do Júlio César de Mello e Souza, que escrevia com o pseudônimo de Malba Tahan.
 Malba Tahan se inspirava na cultura islâmica pra escrever seus livros de divulgação científica, sendo que o mais famoso deles é o Homem Que Calculava. Num post anterior eu tinha dito que o cálculo do Pi com método de monte carlo tinha sido o segundo puzzle que levei mais tempo pra resolver; pois o primeiro puzzle foi justamente tirado de um dos capítulos do livro: como escrever qualquer número usando apenas quatro quatros. No livro, Malba Tahan mostra as soluções até o 10, que são mais ou menos assim:
Malba Tahan se inspirava na cultura islâmica pra escrever seus livros de divulgação científica, sendo que o mais famoso deles é o Homem Que Calculava. Num post anterior eu tinha dito que o cálculo do Pi com método de monte carlo tinha sido o segundo puzzle que levei mais tempo pra resolver; pois o primeiro puzzle foi justamente tirado de um dos capítulos do livro: como escrever qualquer número usando apenas quatro quatros. No livro, Malba Tahan mostra as soluções até o 10, que são mais ou menos assim:0 = 44 - 44
1 = 44 / 44
2 = 4/4 + 4/4
3 = (4 + 4 + 4) / 4
...
Eu tinha só dez anos quando li pela primeira vez, e consegui estender a seqüência até o 20. O posfácio do livro dizia que era possível escrever até o 100, mas eu levei mais de uma década até ver a solução completa!
Depois dos 20 primeiros, eu só consegui fazer algum progresso significativo quando estava no colégio técnico. Eu notei que o problema ficava mais simples se eu reduzisse o número de quatros, montando primeiro todas as soluções com um quatro, depois todas com dois quatros, e assim por diante. Eu não sabia na época, mas o que eu estava fazendo era um forward chaining manual. Mesmo assim, eu só consegui fazer os números pares até 100, minha solução tinha um monte de buracos nos ímpares.
 Quando eu estava na faculdade, com os skillz mais afiados, eu larguei mão de fazer manualmente e escrevi um script pra fazer o serviço automaticamente. Eu coloquei no script não só as quatro operações básicas, mas também todas as outras que estão no Concrete Mathematics: raiz quadrada, função piso e função teto, binomiais, potências, fatorial, fatorial crescente e decrescente. A única regra é não usar nenhuma notação que envolva letras (como sin, cos e log; se você permitir log, o problema perde a graça).
Quando eu estava na faculdade, com os skillz mais afiados, eu larguei mão de fazer manualmente e escrevi um script pra fazer o serviço automaticamente. Eu coloquei no script não só as quatro operações básicas, mas também todas as outras que estão no Concrete Mathematics: raiz quadrada, função piso e função teto, binomiais, potências, fatorial, fatorial crescente e decrescente. A única regra é não usar nenhuma notação que envolva letras (como sin, cos e log; se você permitir log, o problema perde a graça).Meu script conseguiu finalmente resolver todos os números até 100, e até encontrou múltiplas soluções pra eles! Atribuindo um peso a cada operação, eu mandei ele imprimir somente a soluçao mais simples (por exemplo, adição tem peso baixo, piso e teto tem peso alto). A tabela com as respostas está abaixo, junto com o programa que escrevi na época:
Solução gerada pelo script
Script original, escrito em C
O script pode resolver também os 5 cincos, os 6 seis, e qualquer outra combinação, desde que você esteja disposto a esperar o suficiente. O código original é bem ruinzinho, mas na verdade eu me orgulho de achar que meu código escrito há dez anos é ruim, significa que eu aprendi alguma coisa desde então :)
postado por Ricardo Bittencourt às
01:17
|
6 Comentários
Links para esta postagem
![]()