Primos aleatórios
 Dia desses a Alice me perguntou se era possível criar um gerador de números aleatórios que só retornasse números primos. Eu respondi que sim, mas que provavelmente ela não iria gostar da resposta:
Dia desses a Alice me perguntou se era possível criar um gerador de números aleatórios que só retornasse números primos. Eu respondi que sim, mas que provavelmente ela não iria gostar da resposta:int random_prime(int n) {
int x;
do {
x = random(n);
} while (!is_prime(x));
return x;
}Eu sabia que o que ela queria na verdade era uma fórmula bonitinha; então, como esperado, ela não gostou :) Mas a verdade é que esse algoritmo é bem melhor que as alternativas!
Antes de mostrar porque isso é verdade, precisamos formalizar um pouco o problema. É claro que não existem algoritmos que geram números aleatórios: se você quiser aleatoriedade real, precisa pegar alguma fonte física, como o decaimento radiativo. Assumindo então que existe uma fonte física que gera uma distribuiçao uniforme sobre algum intervalo, para criar o algoritmo que retorna números primos aleatórios, basta criar uma função bijetora que leve naturais para primos. Ou seja, uma função que, para um dado um número n, retorne o n-ésimo primo.
O problema é que não existe nenhuma fórmula fechada que calcule isso de maneira eficiente. Você pode calcular alguma constante irracional que resolva o problema, no estilo da constante de Mills, só que mais cedo ou mais tarde a precisão vai te limitar. Você pode calcular o n-ésimo primo com base em alguma outra distribuição, como a função de Möbius, mas aí você só está empurrando o problema com a barriga, porque a outra função é tão difícil de calcular quanto a original.
Uma maneira sem as desvantagens acima é usar o teorema de Wilson pra chegar na seguinte fórmula:
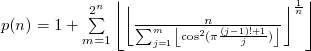
 Mas mesmo essa fórmula ainda está longe do ideal, primeiro porque você vai ter que lidar com números enormes nela (pra n=10 os valores intermediários ficam tão grandes que estouram o limite do que cabe num float), segundo porque, mesmo que você use uma lib para long floats, a complexidade é O(2n), ou seja, mais lento que os programadores do Duke Nukem Forever. Se ainda assim você quiser testar, minha implementação em python é a abaixo:
Mas mesmo essa fórmula ainda está longe do ideal, primeiro porque você vai ter que lidar com números enormes nela (pra n=10 os valores intermediários ficam tão grandes que estouram o limite do que cabe num float), segundo porque, mesmo que você use uma lib para long floats, a complexidade é O(2n), ou seja, mais lento que os programadores do Duke Nukem Forever. Se ainda assim você quiser testar, minha implementação em python é a abaixo:Implementação em python da fórmula acima
Sendo assim, quão melhor era a implementação original por tentativa e erro? Pra avaliar isso, precisamos calcular a complexidade daquele algoritmo. Não é difícil ver que a complexidade do algoritmo como um todo é a complexidade do is_prime() multiplicado pelo valor esperado do número de iterações do loop.
Se você estiver trabalhando numa faixa pequena de primos, pode tabelar todos os primos no intervalo e fazer um is_prime() que seja O(1), mas aí também não tem necessidade da tentativa e erro, você pode indexar seu número aleatório direto na tabela. O caso legal é quando você não pode tabelar, nesse caso você pode implementar o is_prime() usando, por exemplo, o algoritmo AKS, cuja complexidade é O((log n)10.5).
O que resta então é calcular o valor esperado do loop. Lembrando que E[x]=sum(x*p(x)), o que precisamos é calcular qual é a probabilidade de ter uma iteração, duas iterações, e assim por diante. Ora, o teorema dos números primos nos garante que a quantidade de números primos menores que n é assintoticamente igual a n/log(n), então a chance de um número ser primo, num conjunto com n elementos, é 1/log(n). Vamos chamar isso de "p" só pra ficar mais fácil, e o complemento disso é q=1-p, ou seja, a chance de um número não ser primo.
Vejamos então: pra você acertar o primo de primeira, a chance é p. Se você acertar o primo na segunda, a chance é pq. Na terceira, é pq2, na quarta pq3 e assim por diante. Então o valor esperado é:
X = 1p + 2pq + 3pq2 + 4pq3 + ...
X = p (1 + 2q + 3q2 + 4q3 + ....)
Quem tem prática com a transformada z sabe calcular isso de cabeça, mas dá pra calcular também só com matemática elementar. Se você isolar q na soma, fica com:
X = p (1 + q(2 + 3q + 4q2 + ....))
Agora você tira da cartola y=1+q+q2+q3+... e substitui:
X = p (1 + q(2 + 3q + 4q2 + ....))
X = p (1 + q(y + 1 + 2q + 3q2 + ....))
X = p (1 + q(y + X/p)) = p + pqy + pXq/p = p(1+qy) + Xq
X - Xq = p (1 + qy)
X (1-q) = Xp = p (1 + qy)
X = 1 + qy
Mas y é só a soma de uma PG, e isso nós sabemos que vale y=1/(1-q)=1/p. Então:
X = 1 + q/p = (p+q)/p = 1/p
 Como p=1/log(n), então o valor esperado que nós queríamos é tão somente X=log n (vocês também não se impressionam quando tudo simplifica no final?)
Como p=1/log(n), então o valor esperado que nós queríamos é tão somente X=log n (vocês também não se impressionam quando tudo simplifica no final?)É claro que eu não iria resistir à tentação de implementar uma simulação pra ver se o valor bate mesmo. A nossa fórmula diz que, para a faixa de 10 milhões de números, o valor esperado tem que ser da ordem de log(107)=16.1. A simulação abaixo retorna 15.2, bem próximo do valor que foi predito.
Simulação monte carlo do valor esperado, em C++
No fim das contas, a complexidade do algoritmo com tentativa e erro é apenas O(log n), se você tiver um tabelão de primos. Na prática, esse é o método usado por todos que precisam de primos aleatórios: a libgcrypt usada no gpg, por exemplo, utiliza esse método na função gen_prime(), com vários truques pra tornar o teste de primalidade bem rápido.
Marcadores: code, complexidade, cpp, criptologia, math, monte carlo, python
postado por Ricardo Bittencourt às
15:01
|
1 Comentários
Links para esta postagem
![]()