Tutorial de Tradução de Jogos
O Inicio


É curioso como certas manifestações artísticas estão localizadas em locais e tempo bem precisos. O movimento grunge teve seu auge demarcado na Seattle dos anos 90, os quadrinhos de super-heróis tiveram como ápice New York nos idos de 1940. O mesmo aconteceu com os jogos de computadores, que fervilharam no Japão durante a década de 80.
Mas, sendo o Japão tipicamente voltado pro mercado interno, muito pouco do que foi feito naquela época chegou ao ocidente. Para cada Mario e Zelda que chegaram por aqui, dez outros jogos igualmente bons permaneceram desconhecidos por lá!
Hoje em dia todos esses jogos podem ser encontrados facilmente na internet. Entretanto, eles ainda não podem ser apreciados pelos jogadores ocidentais, devido à barreira da linguagem. Tipicamente esses jogos são inteiramente em japonês, sem versão em nenhuma outra língua.
A solução pra isso é a tradução desses jogos. Em novembro de 2001, eu comecei a tradução do jogo Shalom, da Konami, que atualmente está bem próxima da conclusão. Entretanto, ainda existem inúmeros jogos que merecem ser traduzidos!
A proposta deste tutorial é ensinar todas as técnicas e truques necessários para traduzir um jogo. Dessa maneira, espero que sejam disponiblizadas mais dessas pérolas desconhecidas do público de língua portuguesa!
Ao invés de simplesmente fazer uma página com dicas e truques de tradução, resolvi fazer esse tutorial em forma de blog. Dessa maneira, os aspirantes a tradutores podem acompanhar passo a passo o processo de tradução, sem perder nenhum detalhe.
Antes de começar a ler este tutorial, existem alguns avisos que precisam ser feitos. Traduzir um jogo não é fácil. É trabalhoso, cansativo, e requer um série de habilidades que você potencialmente pode não ter.
Como os jogos originais estarão em japonês, você terá que conhecer a língua japonesa antes de qualquer coisa. E apenas conhecer a língua pode não ser suficiente: piadas e trocadilhos podem precisar de conhecimento bastante avançado das estruturas gramaticais, do vocabulário, dos costumes, e da própria história do Japão.
Além disso, em algum ponto você terá que entender o funcionamento do programa, ou pelo menos de parte dele. E se entender código C de outras pessoas, mesmo comentado, é difícil, então, acredite: entender código assembly sem comentários é ainda mais.
Fora os pré-requisitos acima, você ainda terá que ter uma bom conhecimento geral de computação. Ao longo do caminho podem surgir problemas de compressão de dados, conversão de caracteres, falta de memória, e muitos outros. Nesses caso apenas a experiência do programador pode ajudar.
Tendo em vista todos os pepinos listados acima, fuja enquanto é tempo! O botão de Back do seu browser o levará para cantos mais seguros da web! Esse negócio de tradução é coisa pra maluco!
(...)
(...)
(...)
Ok, você está ciente das dificuldades e resolveu continuar lendo. Isso é bom. Traduções requerem mesmo uma boa dose de coragem. Embora todos os problemas listados acima sejam reais, você não precisa atacar todos eles. Se tem uma área que você não conhece, arrume um amigo que conheça. Ninguém disse que a tradução é uma tarefa solitária. E mesmo se você não souber nada, sobre nenhuma das áreas acima, então ainda assim você pode ajudar um projeto de tradução como beta-tester. Sempre sobram bugs que os programadores e tradutores deixam passar.
Terminada a introdução, na próxima lição explicarei o primeiro desafio que o tradutor deve encarar!
A Escolha

Uma das tarefas mais díficeis ao traduzir um jogo, por mais incrível que possa parecer, é escolher o jogo a ser traduzido. O processo de tradução é demorado, penoso, cansativo, por isso é bom ter em mente que o jogo em questão será seu companheiro por meses, ou até anos.
Por isso, a primeira lição que ofereço é: traduza um jogo que você goste. Não adianta muita coisa traduzir um jogo só porque está na moda, ou outro motivo igualmente fútil. Se você realmente não gostar do que está fazendo, as chances que você o abandone no caminho são grandes.
Para esse tutorial, eu tive que escolher um jogo que eu gostasse, e acabei me decidindo por Labyrinth, da Pack-in-Video, jogo baseado no filme homônimo de Jim Henson. Os motivos pelos quais eu sou fã desse filme são longos demais para serem colocados aqui (um dia eu acabo fazendo uma página sobre eles), mas para mim traduzir um jogo baseado em Labyrinth é uma honra. Do ponto de vista estritamente de jogos, basta notar que Labyrinth tem som em MSX-Audio, mas não tem som em FM, e isso já faz dele um jogo único! Além disso, Labyrinth é um RPG, de modo que fica praticamente impossível jogar sem conhecimento de japonês, e isso o coloca na categoria de jogo inédito (ao menos aqui no Ocidente).
Para a próxima lição, um pouco sobre os seus companheiros de trabalho!
As ferramentas de trabalho
Uma das características mais peculiares da língua japonesa é a ausência de Rebelos. De maneira geral, os japoneses não tem o menor pudor em se aproveitar das línguas alheias e apropriar-se de tudo que lhes falta na sua língua nativa.
Isso pode ser comprovado historicamente. Inicialmente o japonês era uma língua estritamente oral. Quando a forma escrita se fez necessária, por volta do século V, os caracteres (kanji) foram importados da China. Já no século XV, o Japão entrou em contato com as civilizações ocidentais, que nessa época estavam em expansão devido às grandes navegações. Por isso, algumas palavras que representavam conceitos novos foram tiradas diretamente da língua dos navegantes portugueses, como pão (パン=pan) e sabão (シャボン=shabon).
Hoje em dia, a fonte dos conceitos novos são os Estados Unidos. Por isso, uma grande quantidade de palavras são copiadas diretamente do inglês, como computador (コンピュータ=konpyuuta) e jogo (ゲーム=geemu). Por esse motivo, é muito comum encontrar palavras, sentenças e até fragmentos inteiros de textos escritos em inglês, dentro de um jogo feito no Japão.
Por outro lado, se os japoneses não se acanham em adaptar palavras e emprestar verbetes, também não fazem muita questão de copiá-los com a grafia correta. Em alguns casos, nem mesmo o significado original é preservado! Um exemplo simples é a palavra para vestido, que no Japão tornou-se ワンピース=wanpiisu, tirado do inglês one piece(!)
Portanto, se você encontrar algum texto em inglês num jogo que veio do Japão, lembre-se desta dica importante: não importa o que está escrito, mas sim o que o autor quis escrever. Como sabiamente disse um japonês nativo amigo meu, "it's not english... it's japanese english!"
Mas deixemos a introdução e vamos ao que interessa. Aplicando diretamente o que foi escrito acima, podemos notar que na tela de créditos do Labyrinth tem um trecho que diz "CODE FOR MSX CONPUTER". Ignorando o que está escrito, percebemos que na verdade o autor quis escrever "CODE FOR MSX COMPUTER". Uma boa tradução passaria todo esse trecho para o português, mas fazer a correção ortográfica é um bom exercício para treinar o uso das ferramentas.
A primeira ferramenta que você precisa para traduzir é um bom emulador. No caso de Labyrinth, um jogo de MSX-2, eu usaria o BrMSX como emulador. Ser o autor do BrMSX ajuda um pouco nessa escolha, é claro, afinal eu sempre posso colocar nele qualquer opção que esteja faltando para ajudar a traduzir. Mas o real motivo da escolha é que ele possui um debugger excelente para disassemblar o código original. Por pura praticidade, eu uso além do BrMSX, também o ParaMSX, ele é muito bom na hora de tirar screenshots.
Verificando que a ROM original roda no emulador, podemos partir para a correção ortográfica propriamente dita. Para isso, vamos usar uma segunda ferramenta: um editor hexa. Eles existem aos montes por aí, mas eu recomendo fortemente o uso do UltraEdit-32. Além da edição hexa propriamente dita, esse soft também possui um editor de textos em unicode, muito apropriado para editar textos em japonês, e um sistema de plug-in onde você pode colocar tanto o emulador quanto a sua ferramenta de extração de scripts. E tudo isso por apenas $35!
Antes de fazer a correção (patch), uma pequena observação. Isso é uma coisa que você já deve ter feito, mas não custa nada lembrar: faça um backup da rom original antes de qualquer alteração.
Para fazer a correção, basta carregar a ROM dentro do UltraEdit-32. Ele deve abrir diretamente em modo hexa, se não acontecer isso, basta apertar CTRL+H. Usando ALT+F3, colocamos a string de busca, no caso, "CONPUTER", e lembre-se de avisá-lo que essa é uma busca de texto, clicando na opção Find ASCII. Basta agora digitar M por cima do N original, salvar a ROM, e testá-la novamente no emulador.


Se tudo correr bem, a essa altura você deve ter uma ROM já corrigida e que funciona normalmente no emulador. Parabéns, você é uma pessoa de sorte! E sorte mesmo, pois apesar do procedimento simples, muita coisa poderia ter dado errado até agora!
Entre as coisas que poderiam acontecer:
- A busca pelo texto "CONPUTER" poderia falhar, se o texto estivesse usando uma codificação diferente de ASCII.
- A busca pelo texto "CONPUTER" poderia falhar, se o texto estivesse comprimido dentro da rom.
- A busca pelo texto "CONPUTER" poderia falhar, se a tela de créditos fosse um bitmap ao invés de texto real.
- A modificação do texto poderia falhar, se a ROM tivesse checksum ou trava contra pirataria.
- Um meteorito poderia cair na sua cabeça (isso não é diretamente relacionado com a tradução, mas poderia acontecer! Você é mesmo um cara de sorte!)
Tendo em mente os problemas que poderiam ter acontecido, é hora de seguir adiante. Na próxima atualização, um pouco de tradução real do japonês para o português!
O conjunto de caracteres
A tradução de jogos é uma daquelas coisas que ficam exponencialmente mais fáceis com a experiência. Na verdade, não tem nenhum método complicado para traduzir: tudo resume-se a um punhado de truques, que com o passar do tempo você aprende e identifica rapidamente quando devem ser usados.
Como disse o amigo sl0wy, do site Hexagon Traduções, eu traduzo jogos há muito anos. Pra ser exato, minha primeira tradução foi em idos de 1987, quando disk drives ainda eram caros demais pra uso pessoal. Na época, eu usava o cartucho Mega Assembler, uma belezinha que trazia embutida editor hexa, busca por string (incluindo busca relativa, com offset qualquer), editor de tiles e de alfabetos, assembler e disassembler, enfim, todas as ferramentas que o tradutor precisa.
E foi brincando com o Mega Assembler que eu fiquei familiarizado com a arquitetura do MSX. Hoje em dia eu conheço todos os detalhes da plataforma, o que torna certos procedimentos da tradução extremamente fáceis. Desse modo, a lição para hoje é estude muito bem a arquitetura da máquina que roda seu jogo, às vezes um pequeno detalhe da arquitetura pode economizar muito do seu tempo!
Problema em questão: a codificação de caracteres. Nós vimos que o texto da tela de créditos está guardado em formato ASCII dentro da ROM, o que torna a edição bastante simples. Mas isso foi para aquele pequeno texto escrito em inglês. E para o restante da ROM, que está em japonês, qual o padrão utilizado?
Se para o ocidente o ASCII é um padrão praticamente universal, o mesmo não se pode dizer da codificação em japonês. Mesmo hoje em dia, existe uma quantidade absurda de sistemas em uso. Visitando sites no Japão você vê páginas escritas em Shift-JIS, algumas em EUC-JP, outras ainda em Unicode. No caso de jogos, muitas vezes não se usa padrão algum, o mais comum é que o jogo tenha uma tabela própria que não é usada em nenhum outro lugar. Shalom, por exemplo, usava uma tabela de 256 posições contendo o hiragana, o katakana e uns 100 kanjis de uso comum. Para descobrir qual tabela era essa, eu abri a rom em um editor de tiles, e localizei dentro dela onde estava o alfabeto. Ou seja, nada muito complicado.
No caso do Labyrinth, entretanto, quem tentar fazer o mesmo não vai achar alfabeto algum. É nesse ponto que os tradutores novatos entram em desespero, acham que deve estar tudo comprimido, que é tudo muito difícil, e desistem. Não façam isso! Este é um caso que resolve-se facilmente quando a arquitetura é bem compreendida.
O que ocorre no MSX é que a ROM do jogo não é o único programa que ele roda. Dentro do próprio computador existe uma BIOS que contém, entre outras coisas, um alfabeto. E pode estar acontecendo do Labyrinth estar usando a o alfabeto interno da rom. A evidência que aponta pra isso é a falta de acentos nos kanas (por exemplo, ao invés de ぜんぶ, o que aparece na tela é せ゛んふ゛). Isso é característico do alfabeto interno da BIOS.


Para provar a teoria, basta utilizar o emulador com uma BIOS diferente. Rodando o jogo com uma BIOS coreana, o texto aparece todo alterado. Isso prova a teoria, e agora podemos assumir com plena certeza que o conjunto de caracteres é mesmo aquele que está na BIOS. Tendo essa informação, na próxima atualização já podemos escrever o script dumper!
Convertendo a tabela
Uma vez descoberto que o alfabeto do jogo está dentro da rom interna do MSX, precisamos agora descobrir qual é o formato que ele usa. Pra isso, a maneira mais fácil é simplesmente abrir a BIOS dentro de um programa gráfico qualquer. Como o alfabeto da BIOS tem só duas cores, preto e branco, as chances são grandes que ele esteja armazenado como um gráfico de 1bpp. E pra visualizar isso tem uma ferramenta ótima chamada Tile Layer Pro.
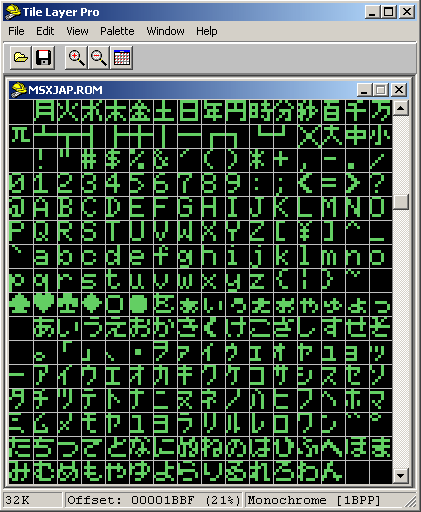
Abrindo a BIOS no Tile Layer Pro, e configurando o software para gráficos monocromáticos (1bpp), basta navegar um pouco para encontrar o alfabeto. Esse tipo de coisa sempre vem em ordem, então para encontrar o código equivalente de cada caractere basta contar, da esquerda pra direita, e de cima pra baixo. Com um pouco de paciência você confere que o caractere A tem código 65. Se você for apressado basta notar que a letra A está na posição 2 da linha 5, e usar notação hexa: subtraindo 1 de cada posição você tem o código hexa 41 (5-1=4, 2-1=1), que convertendo pra decimal confere o 65.
Sabendo o código interno da ROM, só precisamos agora converter para algum código legível em outras ferramentas. Como eu disse anteriormente, o UltraEdit-32 consegue editar textos em japonês, desde que você use formato Unicode. Então basta converter do formato-BIOS para Unicode que o texto ficará pronto para usar. Os códigos Unicode você pega no próprio site oficial do Unicode, onde você aprende, por exemplo, que o código Unicode do caractere あ é 0x3042.
Agora vem a pergunta crucial: tem que fazer isso para todos os 256 caracteres da tabela? A resposta é: sim, tem! Algumas partes do processo de tradução são bastante entediantes, mas alguém tem que fazer isso. Se ninguém fizer essa tabela você não vai conseguir traduzir nada, então o jeito é arregaçar as mangas e mãos à obra!
Para poupá-lo do trabalho de fazer a tabela, você pode pegá-la aqui mesmo, em formato binário. Com ela você já pode criar seu primeiro script dumper! Apresento abaixo uma versão preliminar, de funcionamento bastante simples. Tudo que esse dumper faz é ler byte a byte a informação da rom, e trocar pelo código Unicode equivalente. O código de escape 0xFEFF no começo do script é apenas para indicar que estamos usando uma máquina low-endian, dessa maneira o script gerado pode ser lido em qualquer software compatível com Unicode, em qualquer plataforma.
#include <stdio.h>
#include <io.h>
#include <malloc.h>
#define print(x) c=(x); fwrite (&c,1,2,f);
int main (int argc, char **argv) {
FILE *f;
int len,i;
unsigned char *buf;
unsigned short table[256],c;
f=fopen ("msxtable.out","rb");
fread (table,2,256,f);
fclose (f);
f=fopen (argv[1],"rb");
len=filelength (fileno (f));
buf=(unsigned char *) malloc (len);
fread (buf,1,len,f);
fclose (f);
f=fopen (argv[2],"wb");
print (0xFEFF);
for (i=0; i<len; i++) {
print (table[buf[i]]);
if (i%16==15) {
print (0xD);
print (0xA);
}
}
fclose (f);
return 0;
}
|
Após rodar o programa, você deve estar ansioso para abrir o arquivo e encontrar os textos para traduzir dentro dele, não é? Mas, com exceção daquele texto em inglês da abertura, não há nada inteligível dentro dele! Isso é indicativo que o texto está comprimido ou codificado dentro da ROM, e nesse caso a solução é respirar fundo e partir para o debugging. Na próxima atualização: assembly!
Autor: Ricardo Bittencourt
Copyright © 2002 Ricardo Bittencourt